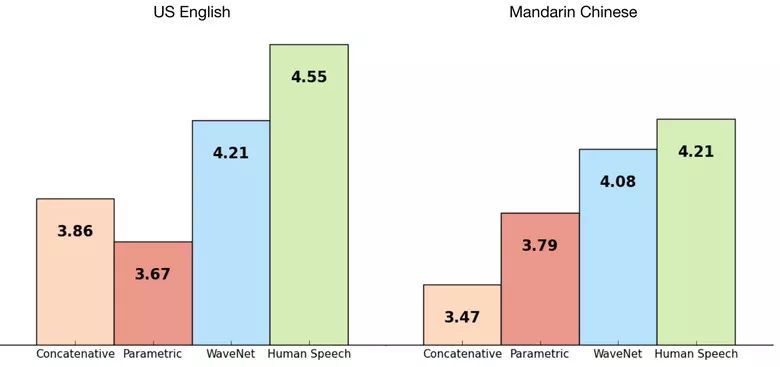
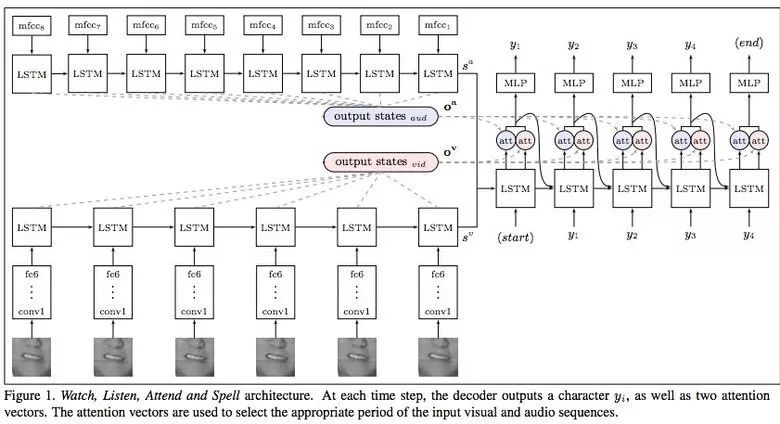
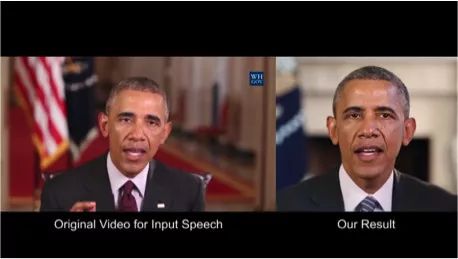
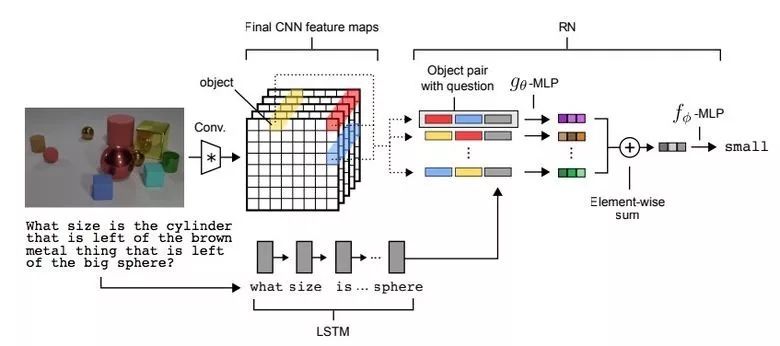
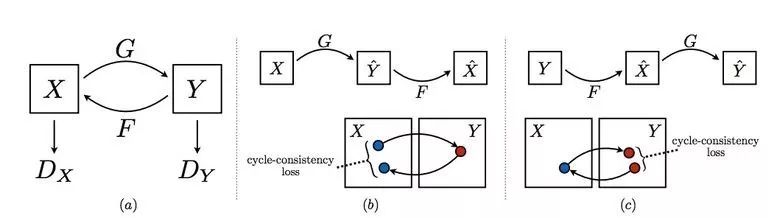
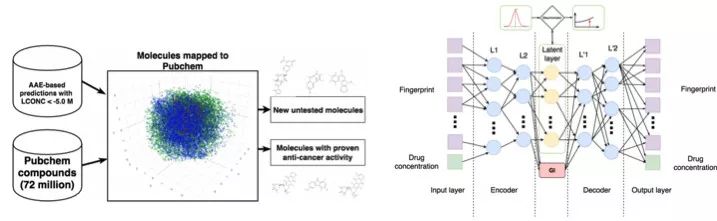
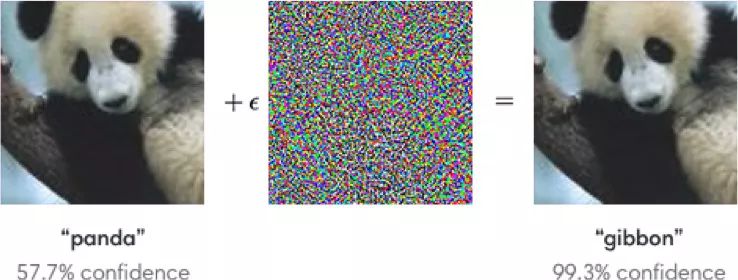
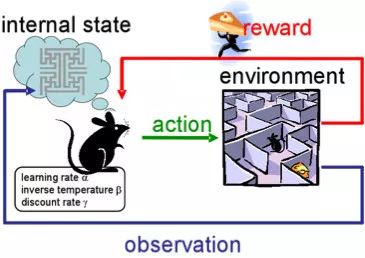
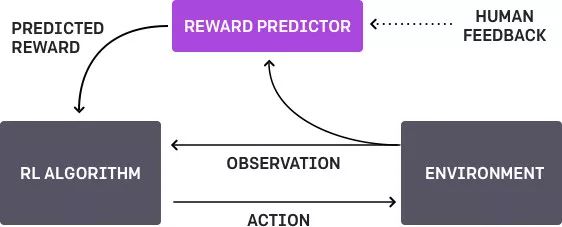
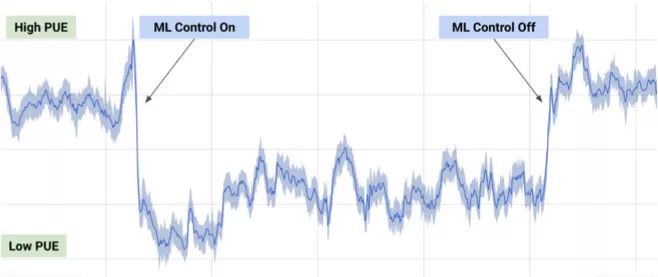
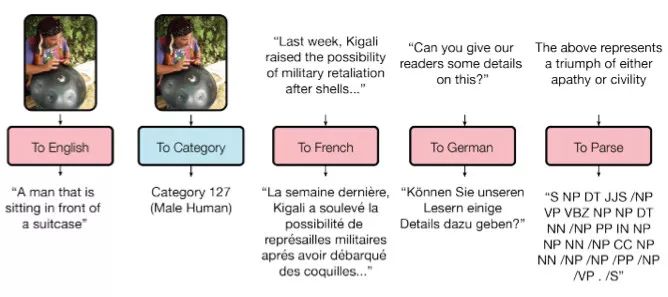
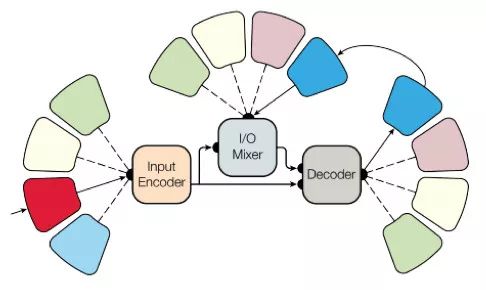
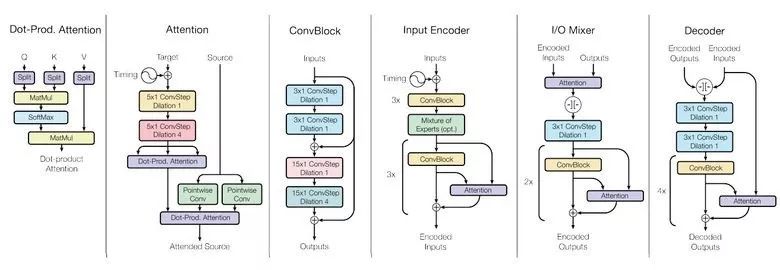
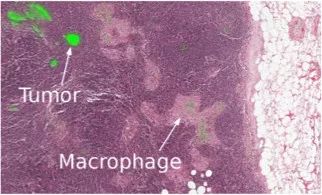
Machine learning will become a basic skill, and learning machine learning will never be late. Artificial intelligence is increasingly penetrating into all areas of technology. Machine Learning (ML) is currently the most active branch. In recent years, ML has made many important advances. Some of them are eye-catching because of the close relationship between the events and the public, while others are low-key but significant. Statsbot has been continuously evaluating the achievements of deep learning. At the end of the year, their team decided to take stock of the achievements of deep learning over the past year. Text 1.1. Google Natural Machine Translation Nearly a year ago, Google released a new generation of Google Translate. The company also introduced the details of its network architecture recurrent neural network (RNN). The key outcome is that the gap between human translation accuracy and accuracy will be reduced by 55%-85% (evaluated by 6 levels). Without a large data set like Google's, it is difficult to reproduce good results with this model. 1.2. Negotiation. Can you trade? You've probably heard of Facebook's stupid news of closing its chat bot because the robot lost control and invented its own language. The purpose of Facebook as a chat bot is to negotiate and negotiate with another agent in order to reach a deal: for example, how to distribute items (books, hats, etc.). Each agent has its own goals when negotiating, but the other party does not know their goals. Negotiations cannot be initiated without a deal. For training purposes, they collected data sets negotiated by humans and trained them in a supervised recursive turbo. Next, they use reinforcement learning to train agents and let them speak to themselves. The condition is that language is similar to humans. The robot learned a real negotiating strategy - pretending to show interest in one aspect of the transaction, and then abandoning this claim to benefit its true goal. This was the first attempt to create such an interactive robot, and the results were quite successful. Of course, it is completely far-fetched to say that this robot invented its own language. When training (consulting with the same agent), they removed the restriction on the similarity between the text and the human, and then the algorithm modified the language of the interaction. nothing special. In the past few years, the development of recursive networks has been very active and applied to many tasks and applications. The architecture of RNN has become much more complicated, but in some areas, a simple forward network, DSSM, can achieve similar results. For example, Google used LSTM to achieve the same quality on the mail function Smart Reply. In addition, Yandex has launched a new search engine based on this type of network. 2. Voice 2.1. WaveNet: The generated model of bare audio DeepMind employees introduced audio generation in the article. Simply put, the researchers made an autoregressive fully convolved WaveNet model based on previous image generation (PixelRNN and PixelCNN). The network is trained end-to-end: text as input and audio output. The study achieved excellent results because the difference from humans was reduced by 50%. The main disadvantage of this type of network is its low productivity. Due to the autoregressive relationship, the sound is serially produced, so one second of audio takes 1 to 2 minutes to generate. Let's take a look... Oh, sorry, listen to this example. If you revoke the network's dependence on the input text, leaving only the reliance on the previously generated phonemes, the network can generate phonemes similar to human language, but such audio is meaningless. Listen to this example of generating speech. The same model can be applied not only to speech, but also to things like music creation. Imagine using this model (training with a data set of a piano game, but also without relying on input data) to generate audio. 2.2. Understanding lips Lip language understanding is another deep learning that transcends human achievements and victories. Google Deepmind collaborated with Oxford University in the article "Lip Language Natural Understanding" to describe how their models (trained through TV datasets) transcend professional lip language interpreters. This data set has a total of 100,000 sentences of audio and video. Model: LSTM for audio and CNN+LSTM for video. These two state vectors are supplied to the last LSTM and then the result (character) is generated. Different types of input data are used during the training: audio, video, and audio and video. In other words, this is a "multi-channel" model. 2.3. Synthetic Obama: Synthesizing lip movements from audio The University of Washington did a serious job, and they generated President Obama’s lip movements. The reason why he chose him is because he has a lot of online videos (17 hours of HD video). They can't make progress on the Internet alone, because there are too many artificial things. Therefore, the author of the article conceived some support (or tricks, if you like to say so) to improve texture and time control. As you can see, the result is amazing. Soon, you can't believe the president's video. 3. Computer vision 3.1. OCR: Google Maps and Street View (Street View) The Google Brain Team reports in blogs and articles how they introduced a new OCR (Optical Character Recognition) engine to Maps, which was then used to identify street nameplates and store signs. In the process of technology development, the company compiled a new FSNS (French street name brand), which contains a lot of complicated situations. In order to identify each brand name, the network utilizes up to 4 photos of famous brands. Features are extracted by CNN, expanded with space help (taking into account pixel coordinates), and then sent to LSTM. The same method is applied to the name of the store on the identification billboard (there is a lot of "noise" data inside, and the network itself must "follow" the appropriate location). This algorithm is applied to 80 billion images. 3.2. Visual reasoning There is a type of task called visual reasoning, and the neural network is asked to answer questions based on a photo. For example: "Is the number of rubber materials in the picture different from the number of yellow metal cylinders?" This problem is not a minor problem. Until recently, the accuracy of the solution was only 68.5%. However, the Deepind team made another breakthrough: they achieved 95.5% accuracy on the CLEVR dataset, even surpassing humans. The architecture of this network is very interesting: Using the pre-trained LSTM on the text question, we got the embedding of the problem. Using CNN (only 4 layers) to the picture, you get the feature map (the characteristics of the inductive picture features) Next, we paired the left segments of the feature map in pairs (yellow, blue, and red in the image below), adding coordinates and text embedding to each. We run all these triples through another network and then aggregate them. The results are presented in a forward feedback network and then the softmax answer is provided. 3.3. Pix2Code Application Uizard created an interesting neural network application: generate layout code based on the screen capture of the interface designer: This is an extremely useful neural network application that can help software development become easier. The authors claim that they achieved 77% accuracy. However, this is still under study and no real use has been discussed. They don't have open source code or datasets yet, but promise to upload them. 3.4. SketchRNN: Teaching Machine Drawing You've probably seen Google's Quick, Draw!, and the goal is to draw sketches of various objects in 20 seconds. The company collected this data set to teach neural network painting, as Google said in their blogs and articles. This data set contains 70,000 sketches, and Google is now open to the public. Sketch is not a picture, but a detailed vector representation of the drawing (the user presses the "pencil" to draw, and when the drawing is finished, the recorded thing is released). Researchers have used RNN as an encoding/decoding mechanism to train the sequence-to-sequence Variational Autoencoder. Ultimately, as a self-encoder, the model will get a feature vector that summarizes the characteristics of the original image. Since the decoder can extract a picture from this vector, you can change it and get a new sketch. Even a vector operation to create a cat: 3.5. GAN (Generate Against Network) Generating a confrontation network (GAN) is one of the hottest topics in deep learning. Many times, this idea is used for images, so I will use images to explain the concept. The idea is embodied in two networks—the game between the generator and the discriminator. The first network authored the image and then tried to understand whether the image was real or generated for the two networks. Explain with the illustration that this is probably the case: During training, the generator generates an image from a random vector (noise) and passes it to the input of the discriminator, which tells whether it is true or false. The discriminator also receives real images from the data set. It is difficult to train such a structure because it is difficult to find a balance point between the two networks. Normally the discriminator will win and the training will be stagnant. However, the advantage of this system is that we can solve the problem that it is difficult for us to set the loss function (for example, to improve the picture quality) - this problem is most appropriate for the discriminator. A typical example of a GAN training result is a picture of a dormitory or person. The idea of ​​generating images using vectors is clearly shown in this project on the face of http://carpedm20.github.io/faces/. You can change the vector to see how the face changes. The same algorithm can also be used for potential space: "a person wearing glasses" minus "one person" plus a "woman" is equivalent to "a woman wearing glasses." 3.6. Changing the age of the face with GAN If you pass control parameters to the potential vector during training, you can change it to manage the necessary images in the image when generating the potential vector. This method is called a conditional GAN. The author of the article "Used Conditional Generation Against the Network for Facial Aging" does just that. After training the engine with an actor of known age in the IMDB dataset, the researcher has the opportunity to change the person's facial age. 3.7. Professional photos Google has found another interesting application for GAN - choosing and improving photos. They train GAN with professional photo data sets: the generator tries to improve bad photos (professional shooting and then degraded with special filters), while the discriminator distinguishes between "improved" photos and real professional photos. The trained algorithm screens the panoramic photos of Google Street View, selects the best of them, and receives professional and semi-professional quality photos (rated by photographers). 3.8. Synthetic images by text description An impressive example of GAN is the use of text to generate images. The authors of the study proposed not only embedding text into the input of the generator (conditional GAN), but also embedding it into the input of the discriminator, thus verifying the relevance of the text to the image. To ensure that the discriminator learns to run his functions, in addition to training, they add incorrect text to the real image. 3.9. Pix2pix application One of the most striking articles in 2016 was Berkeley AI Research (BAIR)'s Image-to-Image Translation with Conditional Confrontation Network. The researchers solved the problem of image-to-image generation, for example, when asked to create a map with a satellite image, or to make a real texture of an object based on a sketch. There is also an example of a conditional GAN ​​success. In this case, the condition is expanded to the entire picture. UNet, which is popular in image segmentation, is used as the architecture of the generator. A new PatchGAN classifier is used as a discriminator to combat blurred images (the picture is divided into N blocks, each of which is predicted for authenticity). Christopher Hesse created a terrible cat image that aroused great interest from users. You can find the source code here. 3.10. CycleGAN image processing tool To apply Pix2Pix, you need a dataset that contains matching pairs of images from different domains. For example, in the case of cards, collecting such data sets is not a problem. However, if you want to do something more complicated, such as "morphing" or stylizing objects, you can't find object matching in general. Therefore, the authors of Pix2Pix decided to perfect their ideas. They came up with CycleGAN to convert images from different fields without specific pairings - "Unpaired Image to Image Translation" The idea is to teach two pairs of generators - the discriminator converts the image from one domain to another, and then vice versa, since we need a loop of consistency - after a series of generator applications, we should get An image similar to the loss of the original L1 layer. In order to ensure that the generator does not convert an image of one domain into another image of the domain that has nothing to do with the original image, a loop loss is required. This approach allows you to learn the horse->zebra mapping. Such conversions are less stable and often create unsuccessful options: The source code can be found here. 3.11. Progress in tumor molecular science Machine learning has now entered the medical industry. In addition to identifying ultrasound, MRI, and making diagnoses, it can also be used to find drugs that fight cancer. We have already reported the details of this study. Simply put, with the help of the Self-Encoder (AAE), you can learn the potential characterization of a molecule and use it to find new molecules. In this way, 69 molecules have been found, half of which are used to fight cancer, and others have significant potential. 3.12. Fighting against attacks The topic of confrontational attacks is very enthusiastic. What is a confrontation attack? For example, a standard network based on ImageNet training is completely unstable after adding special noise to the classified picture. In the example below, we see that the picture that adds noise to the human eye is basically the same, but the model is completely mad and predicts to be a completely different category. The Fast Gradient Sign Method (FGSM) achieves stability: after taking advantage of the parameters of the model, you can advance one to several gradient steps toward the desired category and then change the original image. One of Kaggle's tasks is related to this: Participants are encouraged to build a common offensive and defensive system that will eventually compete against each other to determine the best. Why are we studying these attacks? First, if we want to protect our products, we can add noise to captcha to prevent automatic identification of spammers. Second, algorithms are increasingly penetrating into our lives – such as facial recognition systems and autonomous vehicles. In this case, the attacker will exploit the flaws of these algorithms. Here is an example. You can deceive the facial recognition system through special glass and then "make yourself into another person and get through." Therefore, we need to consider possible attacks when training the model. Such manipulation of the logo also hampers the correct identification of it. Here is a set of articles from the contest organizers. The libraries that have been written for attack: cleverhans and foolbox. 4. Reinforcement learning Reinforcement Learning (RL) is also one of the most interesting developments in machine learning. The essence of this approach is to learn the agent's successful behavior in an environment that rewards through experience—just like a person's lifelong learning. RL is active in games, robotics, and system management (such as transportation). Of course, everyone has heard of Alphago's victory in the game against the best Go players. Researchers used RL in training: the robots play chess on your own to improve the strategy. 4.1. Intensive training of uncontrolled auxiliary tasks In the past few years, DeepMind has learned to play large-scale video games with DQN, which has surpassed humans. Currently, they are teaching algorithms to play more complex games like Doom. A lot of attention has been put into learning acceleration, because the interaction experience of agents and the environment requires many hours of training by modern GPUs. 4.2. Learning robots At OpenAi, they have been actively researching humans' training of agents in virtual environments, which is safer than experimenting in real life. One of their teams showed that one-off learning is possible in one of the studies: a person demonstrates how to perform a specific task in VR, and the results show that a demonstration is enough for the algorithm to learn and then reproduce under real conditions. It would be nice if the church was so simple. 4.3. Learning based on human preferences Here is the work that OpenAi and DeepMind have combined to do. Basically the agent has a task, the algorithm provides two possible solutions to people and then points out which one is better. This process is repeated, and then the algorithm that takes the human 900's word position feedback (binary mark) learns how to solve this problem. As always, humans must be careful to consider what he teaches to the machine. For example, the discriminator determines that the algorithm really wants to take that thing, but in fact he just mimicked the action. 4.4. Movement in complex environments This is another study from DeepMind. In order to teach robots complex behaviors (walking, jumping, etc.) and even doing human-like actions, you have to participate a lot in the choice of loss function, which encourages the desired behavior. However, algorithm learning is better by learning complex behaviors with simple rewards. Researchers have managed to achieve this by teaching complex agents (body simulators) to perform complex actions by building a complex environment with obstacles and providing a simple reward mechanism for processing in motion. You can watch this video and the results are impressive. However, watching with superimposed sounds is much more fun! Finally, I will provide a recently released algorithm link, which OpenAI developed to learn RL. Now you can use a more advanced solution than the standard DQN. 5. Other 5.1. Cooling the data center In July 2017, Google reported that it took advantage of DeepMind's machine learning efforts to reduce data center energy consumption. Based on information from thousands of sensors in the data center, Google developers trained a neural network to predict PUE (energy efficiency) in the data center while performing more efficient data center management. This is an impressive and important example of the practical application of ML. 5.2. Models for all tasks As you know, trained models are very specialized, and each task must be trained for a particular model, making it difficult to move from one task to another. But Google Brain has taken a small step in the universality of the model, "Single Model for Learning Everything" Researchers have trained a model to perform tasks in eight different fields (text, speech, images). For example, translate different languages, text parsing, and image and sound recognition. To achieve this, they developed a complex network architecture with different blocks to process different input data and produce results. The blocks used for encoding/decoding are divided into three types: Convolution, Attention, and Gating Expert Mix (MoE). The main results of the study: A nearly perfect model was obtained (the author did not tune the hyperparameters). Knowledge between different domains has been transformed, that is, performance is almost the same for tasks that require large amounts of data. And it performs better on small issues (say, parsing). The blocks needed for different tasks don't interfere with each other and sometimes help, for example, MoE - it helps with Imagenet tasks. By the way, this model is placed in the tensor2tensor. 5.3. One hour to understand Imagenet Facebook employees told us in an article how their engineers taught the Resnet-50 model to understand Imagenet in just one hour. To be clear, they are used for 256 GPUs (Tesla P100). They used Gloo and Caffe2 for distributed learning. In order to make this process efficient, it is necessary to adopt a large-scale (8192 elements) learning strategy: gradient averaging, warm-up phase, and special learning rate. Therefore, when scaling from 8 GPUs to 256 GPUs, it is possible to achieve 90% efficiency. I don't want ordinary people without such a cluster, and now Facebook researchers can even experiment faster. 6. News 6.1. Unmanned vehicles The development of unmanned vehicles is in full swing and various vehicles are actively testing. In recent years, we have noticed Intel's acquisition of Mobileye, the scandal of former employee stealing technology between Uber and Google, and the first death caused by automatic navigation. I want to emphasize one thing: Google Waymo is launching a beta program. Google is a pioneer in the field, and it thinks its technology is very good because its car has traveled more than 3 million miles. Recently, unmanned vehicles have also been allowed to travel throughout the United States. 6.2. Healthcare As I said, Hyundai ML is beginning to be introduced into the medical industry. For example, Google works with a medical center to help the latter diagnose. Deepmind even set up an independent department. This year Kaggle launched the Data Science Bowl program, a competition that predicts lung cancer for a year. The players are based on a bunch of detailed pictures with a prize pool of $1 million. 6.3 Investment At present, the investment in ML is very large, just like the previous investment in big data. China's investment in AI is as high as 150 billion US dollars, which is intended to be the leader of this industry. In terms of the company, Baidu Research Institute employs 1,300 people, compared to 80 people in FAIR. In the recent KDD, Ali's employees introduced their parameter server KunPeng, which ran 100 billion samples and had 1 trillion parameters. These are "ordinary tasks." You can draw your own conclusions, learning machine learning will never be late. No way, with time, all developers use machine learning, making the latter one of the common skills, just like today's ability to use the database. Copper Flex Membrane Switch panels can be produced using polyester or polyimide (Kapton) as the base material, depending on your interface requirements. A very thin sheet of copper is laminated to the flexible film substrate then chemically etched away, leaving copper traces. The etching process is not environmentally friendly due to the chemicals used, and is also more expensive than screen printing the silver traces used in Silver Flex Membrane Switches. Copper Flex switches can be constructed as: Copper Flex Membrane Switches,Anti Light Leakage Membrane Switch,Fpc Light Membrane Switch,Rim Embossed Membrane Switch Dongguan Nanhuang Industry Co., Ltd , https://www.soushine-nanhuang.com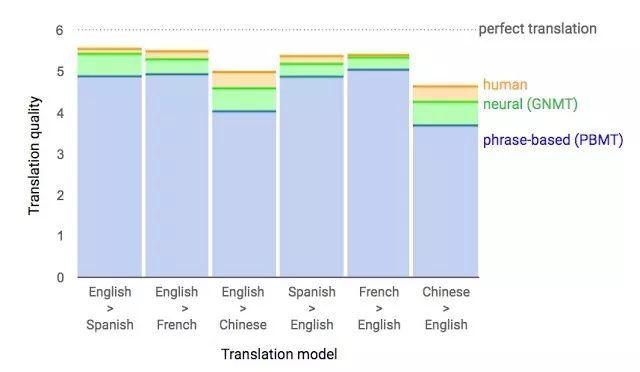








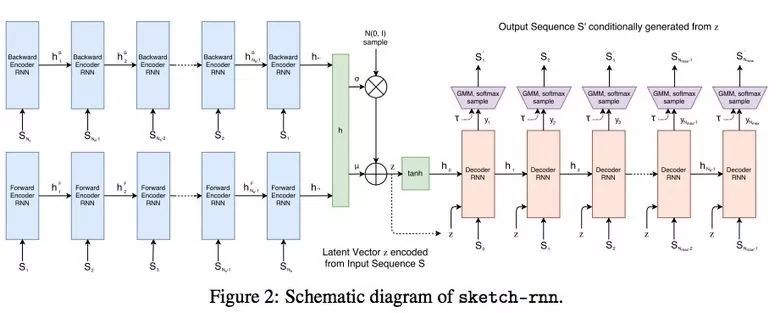
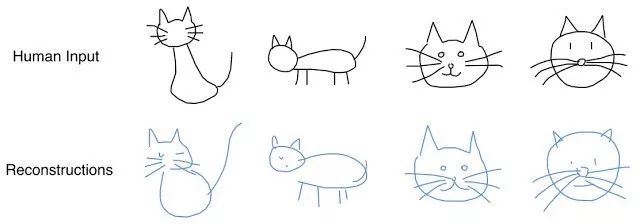

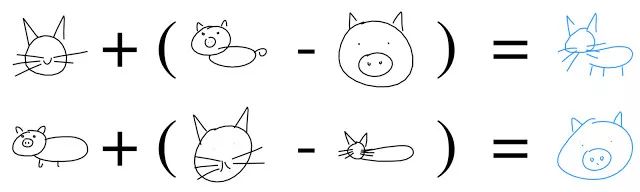
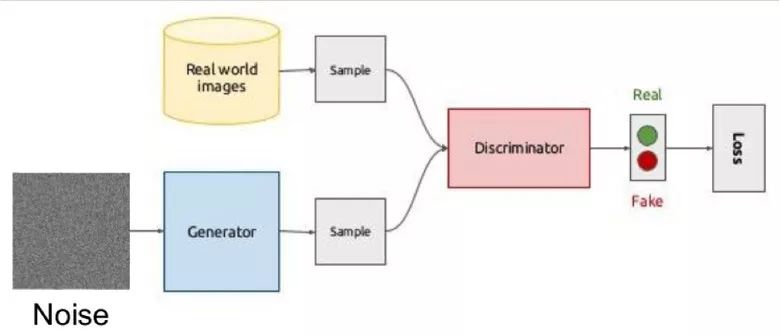

Previously, we discussed self-encoding (Sketch-RNN) that encodes raw data into feature representations. The same thing happens on the generator. 

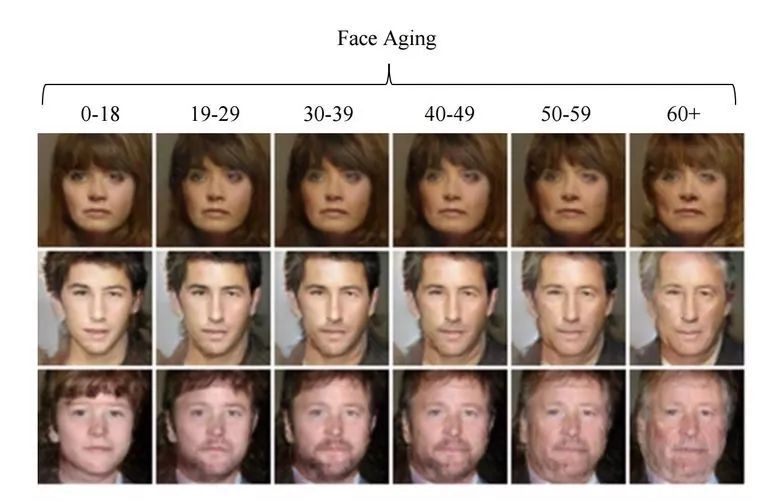



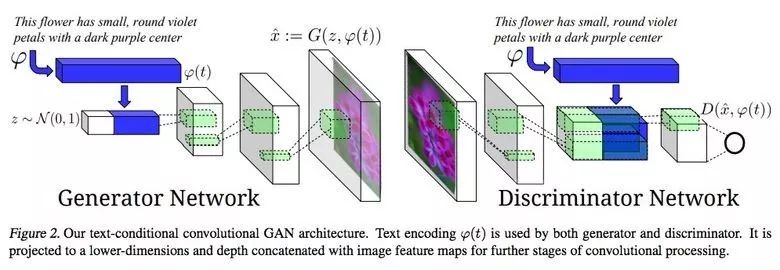

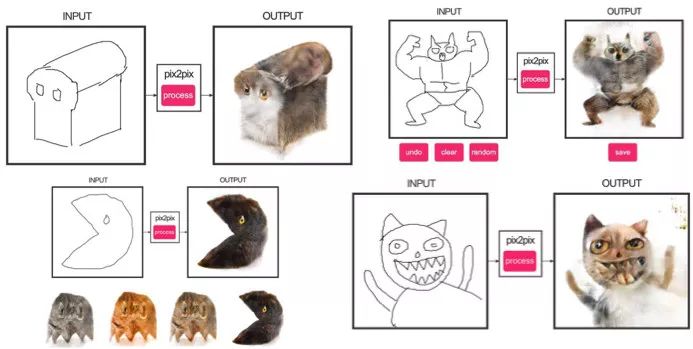







Single-sided – conductive traces one side of the film substrate
Double-sided – conductive traces both sides of the film substrate
Multi-Layer flex – a laminated [sandwich" of numerous layers with conductive traces
Rigid-Flex – a laminated combination of a Copper Flex switch with a rigid FR4 PCB membrane switch